
Функции для работы со строками в кодировке UTF-8
В однобайтовых кодировках символ кодируется одним байтом. Первые 7 бит позволяют закодировать 128 символов, соответствующих кодировке ASCII. Символы, имеющие код меньше 33, являются специальными, например, ну-
левой символ, символ переноса строки, табуляция и т. д. Получить остальные символы позволяет следующий код:
for ($i=33; $i<128; $i++) {
echo $i . " => " . chr($i) . "<br>";
}
Коды этих символов одинаковы практически во всех однобайтовых кодиров- ках. Восьмой бит предназначен для кодирования символов национальных алфавитов. Таким образом, однобайтовые кодировки позволяют закодиро- вать всего 256 символов.
К любому символу строки в однобайтовой кодировке (например, windows-
1251 или KOI8-R) можно обратиться как к элементу массива. Достаточно указать его индекс в квадратных скобках. Нумерация начинается с нуля:
$X = ‘Привет’; // Кодировка windows-1251 или KOI8-R
echo $X[0];
В кодировке UTF-8 один символ может кодироваться несколькими байтами. Первые 128 символов соответствуют кодировке ASCII и кодируются всего одним байтом. Остальные символы кодируются переменным количеством байт от двух до шести (на практике только до четырех). Буквы русского ал- фавита и некоторых других европейских языков кодируются двумя байтами. По этой причине использовать обычные строковые функции нельзя. В дан- ном разделе мы рассмотрим функции, которые можно использовать при ра- боте с кодировкой UTF-8.
Так как в кодировке UTF-8 один символ может кодироваться несколькими байтами, то обратиться к символу как к элементу массива можно только по- сле перекодировки. Тем не менее к символам кодировки ASCII мы можем обратиться как к элементам массива, так как они кодируются одним байтом:
$X = ‘String’; // Кодировка UTF-8 echo $X[0]; // Выведет: S
Если необходимо обращаться к любым символам как к элементам массива,
то можно воспользоваться следующим кодом:
<?php
header(‘Content-Type: text/html; charset=utf-8’);
$str = ‘Строка’;
$count = mb_strlen($str, ‘UTF-8’);
$arr = array();
for ($i=0; $i<$count; $i++) {
$arr[] = mb_substr($str, $i, 1, ‘UTF-8’);
}
echo ‘<pre>’; print_r($arr); echo ‘</pre>’;
?>
О БРАТИТЕ ВНИМ АНИЕ
Для работы PHP с кодировкой UTF-8 необходимо, чтобы в конфигурацион-
ном файле была подключена библиотека php_mbstring.dll.
В главе 4 мы настроили сервер на кодировку windows-1251. Поэтому при ра- боте с UTF-8 необходимо указывать кодировку явным образом. Шаблон про- граммы будет выглядеть так:
<?php
header(‘Content-Type: text/html; charset=utf-8’);
// Сюда вставляем примеры из этого раздела
?>
Кроме того, сам файл необходимо сохранить в кодировке UTF-8. Использо- вать для этого Блокнот нельзя, так как он вставляет в начало файла служеб- ные символы, называемые сокращенно BOM (Byte Order Mark, метка порядка байтов). Для кодировки UTF-8 эти символы не являются обязательными и не позволят нам установить заголовки ответа сервера с помощью функции header(). Для сохранения файлов следует использовать программу Notepad++. В меню Кодировки устанавливаем флажок Кодировать в UTF-8 (без BOM), а затем набираем код. В случае копирования кода через буфер обмена советую вначале сохранить пустой файл в кодировке UTF-8 без BOM, вставить код из буфера обмена, а затем сохранить файл с помощью соответ- ствующей кнопки на панели инструментов.
Для работы со строками в кодировке UTF-8 (а также с другими кодировками)
предназначены следующие функции:
? mb_strlen(<Строка>[, <Кодировка>]) возвращает количество символов в строке:
$str = ‘Строка’;
echo mb_strlen($str, ‘UTF-8’); // Выведет: 6
? iconv_strlen(<Строка>[, <Кодировка>]) возвращает количество симво-
лов в строке:
$str = ‘Строка’;
echo iconv_strlen($str, ‘UTF-8’); // Выведет: 6
? strlen(<Строка>) возвращает количество байт в строке. Так как в одно- байтовых кодировках один символ описывается одним байтом, функция strlen() возвращает количество символов. Для многобайтовых кодиро- вок функция возвращает именно количество байт:
$str = ‘Строка UTF-8’;
echo strlen($str); // Выведет: 18
$str = iconv(‘UTF-8’, ‘windows-1251’, $str);
echo strlen($str); // Выведет: 12
Почему же мы получили 18 байт, а не 24? Все дело в том, что в кодировке UTF-8 первые 128 символов кодируются одним байтом, а все последую- щие символы кодируется несколькими байтами. Каждый символ в слове "Строка" занимает по 2 байта, а в последующей части строки (" UTF-8") каждый символ занимает один байт. Итого 6 умножить на 2 плюс 6 равно
18 байт.
О БРАТИТЕ ВНИМ АНИЕ
Если в конфигурационном файле php.ini директива mbstring.func_overload равна 2 или 7, то функция strlen() полностью эквивалентна функции mb_strlen(). Это означает, что функция strlen() будет возвращать ко- личество символов, а не байт.
? mb_substr() возвращает подстроку указанной длины, начиная с заданной позиции. Если длина не указана, то возвращается подстрока, начиная с заданной позиции и до конца строки. Функция имеет следующий формат:
mb_substr(<Строка>, <Начальная позиция>[, <Длина>[,
<Кодировка>]]);
Пример 1:
$str = ‘Строка’;
$str1 = mb_substr($str, 0, 1, ‘UTF-8’);
echo $str1; // Выведет: C
Пример 2:
mb_internal_encoding(‘UTF-8’); // Установка кодировки
$str = ‘Строка’;
$str2 = mb_substr($str, 1);
echo $str2; // Выведет: трока
Для настройки кодировки необходимо указать ее в четвертом параметре функции mb_substr() или отдельно в функции mb_internal_encoding();
? iconv_substr() возвращает подстроку указанной длины, начиная с за- данной позиции. Если длина не указана, то возвращается подстрока, на- чиная с заданной позиции и до конца строки. Функция имеет следующий формат:
iconv_substr(<Строка>, <Начальная позиция>[, <Длина>[,
<Кодировка>]]);
Пример 1:
$str = ‘Строка’;
$str1 = iconv_substr($str, 0, 1, ‘UTF-8’);
echo $str1; // Выведет: C
Пример 2:
iconv_set_encoding(‘internal_encoding’, ‘UTF-8’);
$str = ‘Строка’;
$str2 = iconv_substr($str, 1);
echo $str2; // Выведет: трока
Для настройки кодировки необходимо указать ее в четвертом параметре функции iconv_substr() или отдельно в функции iconv_set_encoding();
? mb_encode_mimeheader() — позволяет закодировать текст с помощью методов base64 или Quoted-Printable. Функция имеет следующий формат:
mb_encode_mimeheader(<Строка>, [<Кодировка>[,
<Метод кодирования>[, <Символ переноса строк>]]]);
Если параметр <Кодировка> не указан, то используется значение, указан- ное в функции mb_internal_encoding(). Как показывает практика, ука- зывать кодировку в функции mb_internal_encoding() нужно обязатель- но. Параметр <Метод кодирования> может принимать значения "B" (base64) или "Q" (Quoted-Printable). Если параметр не указан, то исполь- зуется значение "B". Параметр <Символ переноса строк> задает символ для разделения строк. По умолчанию предполагается комбинация "\r\n". Пример:
mb_internal_encoding(‘UTF-8’);
$tema = ‘Сообщение’;
echo mb_encode_mimeheader($tema);
// Выведет: =?UTF-8?B?0KHQvtC+0LHRidC10L3QuNC1?=
Для изменения регистра символов предназначены следующие функции:
? mb_strtoupper(<Строка>[, <Кодировка>]) заменяет все символы строки соответствующими прописными буквами:
$str = ‘очень длинная строка’;
echo mb_strtoupper($str, ‘UTF-8’);
// Выведет: ОЧЕНЬ ДЛИННАЯ СТРОКА
? mb_strtolower(<Строка>[, <Кодировка>]) заменяет все символы строки соответствующими строчными буквами:
$str = ‘ОЧЕНЬ длинная строка’;
echo mb_strtolower($str, ‘UTF-8’);
// Выведет: очень длинная строка
? mb_convert_case(<Строка>, <Режим>[, <Кодировка>]) преобразует ре-
гистр символов в зависимости от значения второго параметра. Параметр
<Режим> может принимать следующие значения:
• MB_CASE_UPPER — заменяет все символы строки соответствующими прописными буквами;
• MB_CASE_LOWER — заменяет все символы строки соответствующими строчными буквами;
• MB_CASE_TITLE — делает первые символы всех слов прописными.
Примеры:
$str = ‘ОЧЕНЬ длинная строка’;
echo mb_convert_case($str, MB_CASE_UPPER, ‘UTF-8’);
// Выведет: ОЧЕНЬ ДЛИННАЯ СТРОКА
echo ‘<br>’;
echo mb_convert_case($str, MB_CASE_LOWER, ‘UTF-8’);
// Выведет: очень длинная строка
echo ‘<br>’;
echo mb_convert_case($str, MB_CASE_TITLE, ‘UTF-8’);
// Выведет: Очень Длинная Строка
echo ‘<br>’;
mb_internal_encoding(‘UTF-8’); // Установка кодировки
echo mb_convert_case($str, MB_CASE_UPPER);
// Выведет: ОЧЕНЬ ДЛИННАЯ СТРОКА
Для поиска в строке используются следующие функции:
? mb_strpos() ищет подстроку в строке. Возвращает номер позиции, с ко- торой начинается вхождение подстроки в строку. Если подстрока в стро- ку не входит, то функция возвращает false. Функция зависит от регистра символов. Имеет следующий формат:
mb_strpos(<Строка>, <Подстрока>[, <Начальная позиция поиска>[,
<Кодировка>]]);
Если начальная позиция не указана, то поиск будет производиться с на-
чала строки:
echo mb_strpos(‘Привет’, ‘ри’, 0, ‘UTF-8’); // Выведет: 1 mb_internal_encoding(‘UTF-8’); // Установка кодировки
if (mb_strpos(‘Привет’, ‘При’) !== false) echo ‘Найдено’;
// Выведет: Найдено
else echo ‘Не найдено’;
? iconv_strpos() ищет подстроку в строке. Возвращает номер позиции, с которой начинается вхождение подстроки в строку. Если подстрока в строку не входит, то функция возвращает false. Функция зависит от ре- гистра символов. Если начальная позиция не указана, то поиск будет производиться с начала строки. Функция имеет следующий формат:
iconv_strpos(<Строка>, <Подстрока>[, <Начальная позиция поис-
ка>[,
Примеры:
<Кодировка>]]);
echo iconv_strpos(‘Привет’, ‘ри’, 0, ‘UTF-8’); // Выведет: 1 if (iconv_strpos(‘Привет’, ‘При’, 0, ‘UTF-8’) !== false)
echo ‘Найдено’;
// Выведет: Найдено
else echo ‘Не найдено’;
? mb_stripos() ищет подстроку в строке. Возвращает номер позиции, с которой начинается вхождение подстроки в строку. Если подстрока в строку не входит, то функция возвращает false. В отличие от функции mb_strpos() не зависит от регистра символов. Имеет следующий формат:
mb_stripos(<Строка>, <Подстрока>[, <Начальная позиция поиска>[,
<Кодировка>]]);
Пример:
echo mb_stripos(‘Привет’, ‘РИ’, 0, ‘UTF-8’); // Выведет: 1
Если начальная позиция не указана, то поиск будет производиться с на-
чала строки;
? mb_strrpos() ищет подстроку в строке. Возвращает позицию последнего вхождения подстроки в строку. Если подстрока в строку не входит, то функция возвращает false. Функция зависит от регистра символов. Име- ет следующий формат:
mb_strrpos(<Строка>, <Подстрока>[, <Начальная позиция поиска>[,
<Кодировка>]]);
Если начальная позиция не указана, то поиск будет производиться с на-
чала строки:
echo mb_strrpos(‘ерпарверпр’, ‘ер’, 0, ‘UTF-8’); // Выведет: 6
? iconv_strrpos() ищет подстроку в строке. Возвращает позицию послед- него вхождения подстроки в строку. Если подстрока в строку не входит, то функция возвращает false. Функция зависит от регистра символов. Имеет следующий формат:
iconv_strrpos(<Строка>, <Подстрока>[, <Кодировка>]);
Пример:
echo iconv_strrpos(‘ерпарверпр’, ‘ер’, ‘UTF-8’); // Выведет: 6
? mb_strripos() ищет подстроку в строке. Возвращает позицию последне- го вхождения подстроки в строку. Если подстрока в строку не входит, то функция возвращает false. В отличие от функции mb_strrpos() не зави- сит от регистра символов. Имеет следующий формат:
mb_strripos(<Строка>, <Подстрока>[, <Начальная позиция поиска>[,
<Кодировка>]]);
Если начальная позиция не указана, то поиск будет производиться с на-
чала строки:
echo mb_strripos(‘ерпарверпр’, ‘ЕР’, 0, ‘UTF-8’); // Выведет: 6
? mb_substr_count() возвращает число вхождений подстроки в строку.
Функция зависит от регистра символов. Имеет следующий формат: mb_substr_count(<Строка>, <Подстрока>[, <Кодировка>]); Пример:
echo mb_substr_count(‘ерпаерпр’, ‘ер’, ‘UTF-8’); // Выведет: 2
Как вы уже наверняка заметили, параметр <Кодировка> во всех этих функци-
ях является необязательным.
Если параметр не указан, то:
? при использовании функций, начинающихся с префикса "mb_", исполь- зуется значение директивы mbstring.internal_encoding или значение, указанное в функции mb_internal_encoding();
? при использовании функций, начинающихся с префикса "iconv_", ис- пользуется значение директивы iconv.internal_encoding или значение, указанное в функции iconv_set_encoding().
Для преобразования кодировок можно использовать функции iconv() и
mb_convert_encoding() (см. разд. 5.15.7).
Некоторые обычные строковые функции также можно использовать при ра-
боте с кодировкой UTF-8:
? str_replace() — для замены в строке;
? htmlspecialchars() — для замены специальных символов их HTML-
эквивалентами. Кодировка указывается в третьем параметре;
? trim(), ltrim() и rtrim() — для удаления пробельных символов в нача- ле и (или) конце строки. Если во втором параметре указать список симво- лов (например, русских букв), то функции будут работать некорректно;
? addslashes() — для добавления защитных слэшей перед специальными символами;
? stripslashes() — для удаления защитных слэшей.
Функции trim(), addslashes() и stripslashes() можно использовать, так как они удаляют (или добавляют) символы, которые в UTF-8 кодируются од- ним байтом. Все эти функции мы уже рассматривали в разд. 5.15.1. Кроме перечисленных функций для кодирования и шифрования строк можно ис- пользовать функции, рассмотренные в разд. 5.15.6.
Если необходимо использовать регулярные выражения для поиска или заме- ны в строке, то следует применять Perl-совместимые регулярные выражения (PCRE). Так как мы работаем с кодировкой UTF-8, то в параметре <Модифи- катор> обязательно должен присутствовать модификатор u. В качестве при- мера удалим все русские буквы из строки:
$str = ‘строка1строка2строка3’;
echo preg_replace(‘#[а-яё]#isu’, ”, $str); // 123
О БРАТИТЕ ВНИМ АНИЕ
Регистр модификатора u имеет значение.
Если в этом примере модификатор u не указать, то будет удален один байт из каждого двухбайтового символа и в итоге в строке появятся "квадратики" или знаки вопроса.
5.15.11. Перегрузка строковых функций
Некоторые функции, предназначенные для работы с однобайтными кодиров- ками, можно перегрузить в файле конфигурации php.ini или с помощью фай- ла .htaccess. После перегрузки функции могут корректно работать с много- байтовыми кодировками. Перегрузка функций осуществляется с помощью директивы mbstring.func_overload. Директива может принимать следую- щие значения:
? 0 — без перегрузки (значение по умолчанию);
? 1 — функция для отправки писем mail() будет эквивалентна функции
mb_send_mail();
? 2 — будут перегружены строковые функции. Список функций приведен в табл. 5.1;
? 4 — перегрузка функций, предназначенных для работы с регулярными выражениями формата POSIX. Список функций приведен в табл. 5.2. Вместо этих функций лучше использовать функции, предназначенные для работы с Perl-совместимыми регулярными выражениями;
? 7 — все указанные ранее функции будут перегружены.
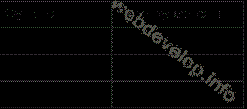
Таблица 5.1. Перегрузка строковых функций
|
Функция |
Перегружается в |
|
strlen() |
mb_strlen() |
|
substr() |
mb_substr() |
|
strtoupper() |
mb_strtoupper() |
|
strtolower() |
mb_strtolower() |
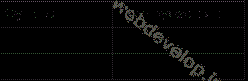
Таблица 5.2. Перегрузка функций, предназначенных для работы с регулярными выражениями формата POSIX
|
Функция |
Перегружается в |
|
ereg() |
mb_ereg() |
|
eregi() |
mb_eregi() |
|
ereg_replace() |
mb_ereg_replace() |
Для корректной работы функций после перегрузки необходимо указать ко-
дировку в директиве mbstring.internal_encoding.
Источник: Прохоренок Н. А. HTML, JavaScript, PHP и MySQL. Джентльменский набор Web-мастера. — 3-е изд., перераб. и доп. — СПб.: БХВ-Петербург, 2010. — 912 с.: ил. + Видеокурс (на CD-ROM) — (Профессиональное программирование)
Похожие посты:
- Вывод текста с отступом (0)
- Изменение фонового цвета строки при наведении на нее указателя мыши (0)
- Конфигурация URL и слабая связанность (0)
- Красиво отформатированные страницы ошибок в Django (0)
- Простая проверка данных Django (0)
- Углубленное изучение представлений и конфигурации URL (0)
- Аргументы представления, принимаемые по умолчанию Django (0)